Cosa cosa tratta questo articolo?
In questo articolo, inizieremo a interrogare CSV e JSON in Google Cloud Storage (GCS) e creeremo nuove tabelle da tabelle esistenti (processo ETL). Questo articolo è principalmente per gli sviluppatori BI che vogliono espandere le loro capacità per gestire i Big Data e terminato con successo la prima parte.
Creare Tabelle
In questo caso, dovevo creare 2 tabelle che contengono i dati di YouTube dal Google Storage.
Presenterò due esempi: uno su File CSV e un altro su File JSON, puoi trovarli in questo link.
Successivamente, creeremo tabelle per quei file e uniremo entrambe le tabelle.
L'intero processo è il seguente:
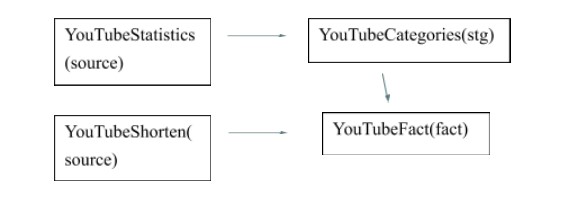
Interroga i file CSV
- Scarica i file CSV allegati. Poiché i dati sono strutturati, questo caso d'uso è più semplice.
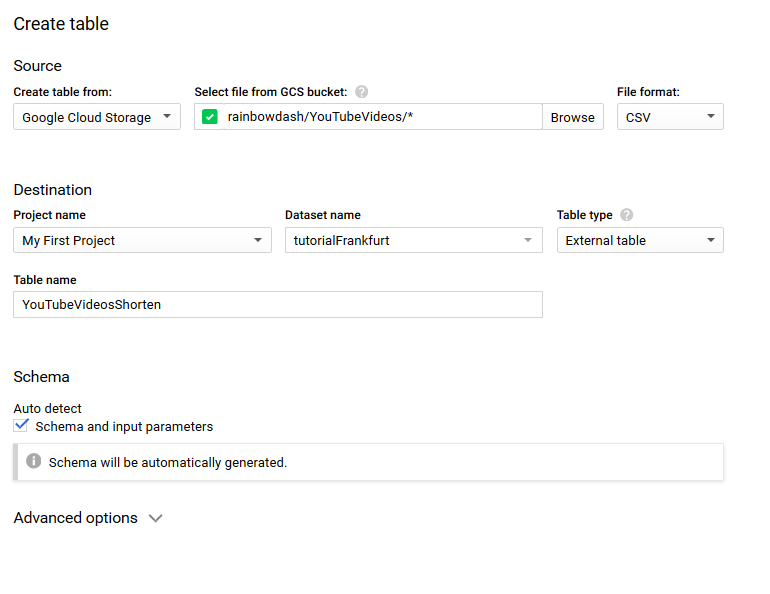
La tabella è per il livello di ingestione (MRR) e deve essere denominata - YouTubeVideosShorten.
- Crea una nuova cartella nel tuo contenitore denominata YouTubeVideos e inserisci i file lì.
- Crea la tabella in Big Query. (puoi vedere la mia configurazione nella seguente immagine)
- Dopo aver creato la tabella, assicurati di visualizzare la tabella nell'elenco delle tabelle.
- Ora: richiedi i tuoi dati, ad esempio:
SELECT
SUBSTR(_FILE_NAME, LENGTH('gs://rainbowdash/YouTubeVideos/') + 1, 2 ) country,
V.video_id,
V.title,
V.category_id,
V.tags,
V.views,
V.likes,
V.dislikes,
V.comment_count,
CAST(PARSE_DATE('%y.%d.%m',
V.trending_date ) AS TIMESTAMP) trending_date,
V.publish_time publish_time,
TIMESTAMP_DIFF(CAST(PARSE_DATE('%y.%d.%m',
V.trending_date ) AS TIMESTAMP), V.publish_time, HOUR) duration
FROM
`big-passage-263811.tutorialFrankfurt.youtubevideosshorten` V
In questo caso, utilizziamo la tabella come "Esterno" e calcoliamo la durata di ogni video alla moda dal suo caricamento. Selezioniamo anche le prime 2 lettere di ogni file e otteniamo il nostro paese.
Interroga i file JSON
Poiché i dati sono semi-strutturati, questo caso d'uso è un po 'più difficile YouTubeStatisctics della Tabella di Ingestion Level (MRR).
- Scarica i file JSON allegati. Poiché i dati sono strutturati, questo caso d'uso è più semplice.
La tabella è per il livello di ingestione (MRR) e dovrebbe essere denominata - YouTubeStatisctics.
- Crea una nuova cartella nel tuo secchio denominata YouTubeStatistics e inserisci i file lì.
- Crea la tabella in Big Query. (puoi vedere la mia configurazione nella seguente immagine)
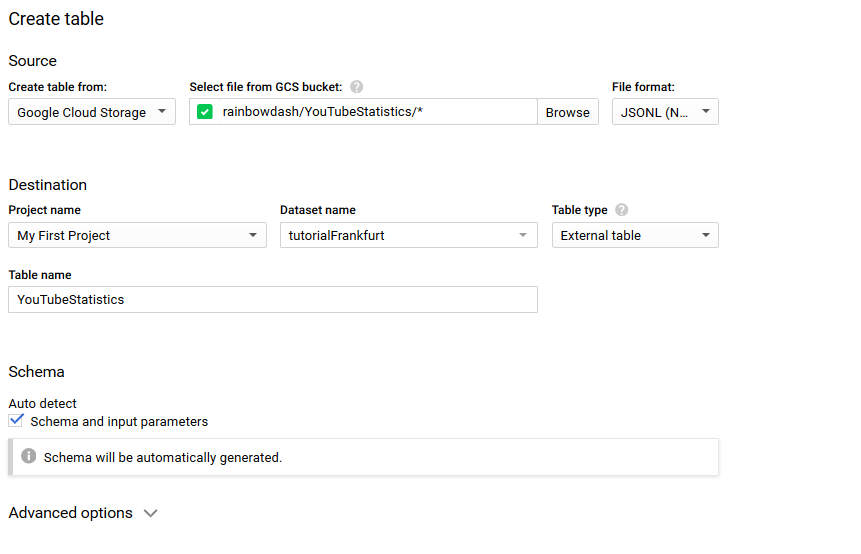
- Dopo aver creato la tabella, assicurati di visualizzare la tabella nell'elenco delle tabelle.
- Ora, ad esempio, richiedi i tuoi dati:
SELECT
SUBSTR(_FILE_NAME, LENGTH('gs://rainbowdash/YouTubeStatistics/') + 1, 2 ) country,
json_.kind kind1,
json_.etag etag1,
inr,
inr.kind,
inr.etag,
inr.id,
inr.snippet.channelid,
inr.snippet.title,
inr.snippet.assignable
FROM
`big-passage-263811.tutorialFrankfurt.YouTubeStatistics` json_,
UNNEST(items) inr
**In questo caso usiamo la tabella come "Esterno"
** Notare che la funzione UNNEST () esplode il JSON (che è 1 riga di {kind, etag, list of other object}) e alloca il tipo e etag a tutte le altre righe.
Creazione di una nuova tabella
- La nuova tabella che creiamo verrà denominata -
- Estraeremo le categorie dal file Json.
- Esegui la seguente query:
SELECT
SUBSTR(_FILE_NAME, LENGTH('gs://rainbowdash/YouTubeStatistics/') + 1, 2 ) country,
inr.id id,
inr.snippet.title title
FROM
`big-passage-263811.tutorialFrankfurt.YouTubeStatistics` json_,
UNNEST(items) inr
- Dopo l'esecuzione della query, fai clic su "Salva risultati", fai clic su "BigQuery" e quindi su "Salva".
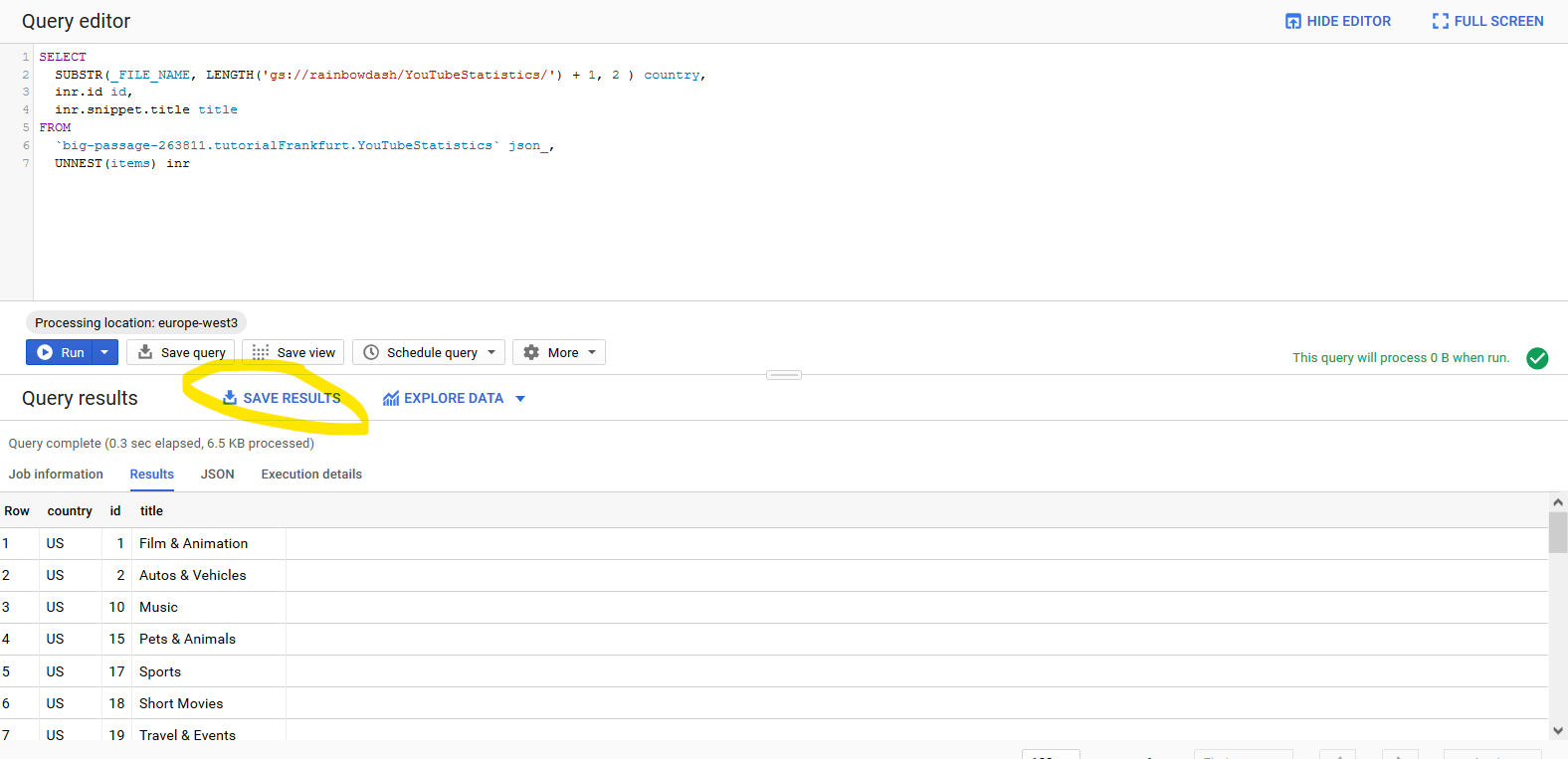
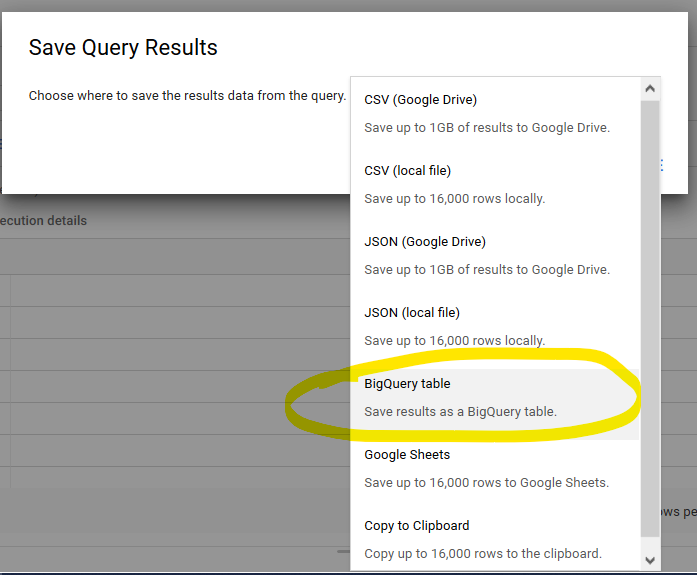
- Dai a questa tabella il nome "YouTubeCategories", quindi salvalo.
- Assicurati di poter ora visualizzare questa tabella nell'elenco delle tabelle.
Joining delle Tabelle
- In questo passaggio uniremo le tabelle: YouTubeCategories e YouTubeVideosShorten.
- Dobbiamo unire queste tabelle per Categoria_Id e per Paese.
- Ecco il codice SQL per la richiesta:
SELECT
V.country,
V.video_id,
V.title,
C.title category,
V.tags,
V.views,
V.likes,
V.dislikes,
V.comment_count,
CAST(PARSE_DATE('%y.%d.%m',
V.trending_date ) AS TIMESTAMP) trending_date,
V.publish_time publish_time,
TIMESTAMP_DIFF(CAST(PARSE_DATE('%y.%d.%m',
V.trending_date ) AS TIMESTAMP), V.publish_time, HOUR) duration
FROM (
SELECT
SUBSTR(_FILE_NAME, LENGTH('gs://rainbowdash/YouTubeVideos/') + 1, 2 ) country,
*
FROM
`big-passage-263811.tutorialFrankfurt.youtubevideosshorten`) V
LEFT JOIN
`big-passage-263811.tutorialFrankfurt.YouTubeCategories` C
ON
V.category_id = C.id
AND V.country = C.country
- Ora puoi inserire il tuo risultato in un'altra tabella (YouTubeFact).
** Si noti che le ultime 2 tabelle sono tabelle native, quindi i dati sono in BigQuery e non in Google Storage.
Vantaggi:
- Il processo che ho sviluppato qui non è la migliore prassi (YouTubeShorten dovrebbe essere trasformato prima di unirla a YouTubeCategories: puoi dirne il perché?).
- Prova a sviluppare una tabella STG per youtubeshorten prima di unirla a categorie.
- Tieni presente che lo schema della tabella dei fatti non deve essere modificato.
- Prossime sessioni:
- Usare le partizioni
- Salva i dati come colonne
- Perché facciamo queste due cose? Perché vogliamo risparmiare denaro.




